Tin Kien Giang K31
Chao mung den voi dien dan Tin-KG Khoa 31
|
| | | Mã Hamming |  |
| | | Tác giả | Thông điệp |
|---|
nguyenkienkgs
Moderator

Tổng số bài gửi : 23
Registration date : 15/09/2007
 |  Tiêu đề: Mã Hamming 14/10/2007, 20:02 Tiêu đề: Mã Hamming 14/10/2007, 20:02 | |
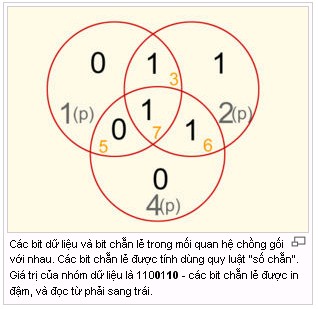
| I .Giới thiệuTrong viễn thông (telecommunication), mã Hamming là một mã sửa lỗi tuyến tính (linear error-correcting code), được đặt tên theo cái tên của người chủ sáng tạo nó, ông Richard Hamming. Mã Hamming có thể phát hiện một bit hoặc hai bit bị lỗi (single and double-bit errors). Mã Hamming còn có thể sửa các lỗi do một bit bị sai gây ra. Ngược lại với mã của ông, mã chẵn lẻ (parity code) đơn giản vừa không có khả năng phát hiện các lỗi khi 2 bit cùng một lúc bị hoán vị (0 thành 1 và ngược lại), vừa không thể giúp để sửa được các lỗi mà nó phát hiện thấy. II. Lịch sửTrong những năm của thập niên kỷ 1940, Hamming làm việc tại Bell Labs trên máy tính Bell Model V, một máy điện cơ (electromechanical) dùng rơ-le (relay-based), với tốc độ rất chậm, mấy giây đồng hồ một chu kỳ máy. Nhập liệu được cho vào máy bằng những cái thẻ đục lỗ (punch cards), và hầu như máy luôn luôn gây lỗi trong khi đọc. Trong những ngày làm việc trong tuần, những mã đặc biệt được dùng để tìm ra lỗi và mỗi khi tìm được, nó nhấp nháy đèn báo hiệu, báo cho người điều khiển biết để họ sửa, điều chỉnh máy lại. Trong thời gian ngoài giờ làm việc hoặc trong những ngày cuối tuần, khi người điều khiển máy không có mặt, mỗi khi có lỗi xảy ra, máy tính tự động bỏ qua chương trình đương chạy và chuyển sang công việc khác. Hamming thường làm việc trong những ngày cuối tuần và ông càng ngày càng trở nên bực tức mỗi khi ông phải khởi động lại các chương trình ứng dụng từ đầu, do chất lượng kém, không đáng tin cậy (unreliability) của bộ máy đọc các thẻ đục lỗ. Mấy năm tiếp theo đó, ông dồn tâm lực vào việc xây dựng hằng loạt các thuật toán có hiệu quả cao để giải quyết vấn đề sửa lỗi. Năm 1950, ông đã công bố một phương pháp mà hiện nay được biết là Mã Hamming. Một số chương trình ứng dụng hiện thời vẫn còn sử dụng mã này của ông. III.Các mã trước thời kỳ của HammingNhiều mã phát hiện lỗi đơn giản đã được sử dụng trước khi có mã Hamming, nhưng không có mã nào hiệu quả bằng mã Hamming với một tổng phí tương đương. a . Mã chẵn lẻMã chẵn lẻ thêm một bit vào trong dữ liệu, và bit cho thêm này cho biết số lượng bit có giá trị 1 của đoạn dữ liệu nằm trước là một số chẵn hay một số lẻ. Nếu một bit bị thay đổi trong quá trình truyền dữ liệu, giá trị chẵn lẻ trong thông điệp sẽ thay đổi và do đó có thể phát hiện được lỗi (Chú ý rằng bit bị thay đổi có thể lại chính là bit kiểm tra). Theo quy ước chung, bit kiểm tra có giá trị bằng 1 nếu số lượng bit có giá trị 1 trong dữ liệu là một số lẻ, và giá trị của bit kiểm tra bằng 0 nếu số lượng bit có giá trị 1 trong dữ liệu là một số chẵn. Nói cách khác, nếu đoạn dữ liệu và bit kiểm tra được gộp lại cùng với nhau, số lượng bit có giá trị bằng 1 luôn luôn là một số chẵn. Việc kiểm tra dùng mã chẵn lẻ là một việc không được chắc chắn cho lắm, vì nếu số bit bị thay đổi là một số chẵn (2, 4, 6 - cả hai, bốn hoặc sáu bit đều bị hoán vị) thì mã này không phát hiện được lỗi. Hơn nữa, mã chẵn lẻ không biết được bit nào là bit bị lỗi, kể cả khi nó phát hiện là có lỗi xảy ra. Toàn bộ dữ liệu đã nhận được phải bỏ đi, và phải truyền lại từ đầu. Trên một kênh truyền bị nhiễu, việc truyền nhận thành công có thể mất rất nhiều thời gian, nhiều khi còn không truyền được nữa. Mặc dù việc kiểm tra bằng mã chẵn lẻ không được tốt cho lắm, song vì nó chỉ dùng 1 bit để kiểm tra cho nên nó có số tổng phí (overhead) thấp nhất, đồng thời, nó cho phép phục hồi bit bị thất lạc nếu người ta biết được vị trí của bit bị thất lạc nằm ở đâu. Bit chẵn lẻ (tiếng Anh: parity bit) là một bit dùng để báo hiệu số lượng bit có giá trị bằng 1(2) trong một nhóm bit cho trước là một số chẵn hay là một số lẻ. Bit chẵn lẻ được sử dụng như là một mã dùng để phát hiện lỗi đơn giản nhất.
Có hai loại mã chẵn lẻ: bit chẵn lẻ dùng quy luật số chẵn (even parity bit) và bit chẵn lẻ dùng quy luật số lẻ (odd parity bit). Bit chẵn lẻ dùng quy luật số chẵn có giá trị bằng 1(2) khi số lượng các bit 1, trong một nhóm bit cho trước, là một số lẻ (và khi cộng thêm bit chẵn lẻ vào, tổng số lượng bit có giá trị bằng 1(2) là một số chẵn). Ngược lại, bit chẵn lẻ dùng quy luật số lẻ có giá trị bằng 1(2) nếu số lượng các bit 1, trong một nhóm bit cho trước, là một số chẵn (và khi cộng thêm bit chẵn lẻ vào, tổng số bit có giá trị bằng 1(2) là một số lẻ). Bit chẵn lẻ dùng quy luật chẵn là một trường hợp đặc biệt của kỹ thuật kiểm tra độ dư tuần hoàn (cyclic redundancy check - CRC). Trong CRC, bit CRC được kiến tạo bằmg cách dùng đa thức (polynomial) x+1. Phát hiện lỗi Phát hiện lỗi
Nếu một số lẻ lượng các bit (bao gồm cả bit chẵn lẻ), bị đảo lộn trong khi truyền thông một nhóm bit, thì bit chẵn lẻ sẽ có giá trị không đúng, và do đó báo hiệu rằng lỗi trong truyền thông đã xảy ra. Với lý do này, bit chẵn lẻ còn được gọi là một mã phát hiện lỗi, song nó không phải là một mã sửa lỗi, vì nó chẳng có cách nào xác định được vị trí của bit bị lỗi cả. Khi lỗi bị phát hiện, dữ liệu thu được phải bị bỏ đi và phải được truyền thông lại từ đầu. Trên kênh truyền có độ nhiễu cao, việc truyền tải dữ liệu thành công là một việc rất hao tốn thời gian, và đôi khi, việc truyền thông còn hầu như không thể thực hiện được nữa. Bit chẵn lẻ có một ưu điểm: nó là một mã tốt nhất chiếm chỉ một bit và chỉ dùng vài cồng XOR (XOR gate) để tạo giá trị mà thôi. Ứng dụngDo đặc tính đơn giản của nó, bit chẵn lẻ được dùng trong rất nhiều ứng dụng phần cứng, những nơi mà việc tái diễn các thao tác khi có trục trặc xảy ra là một việc có thể thực hiện được, hoặc những nơi mà việc phát hiện lỗi đơn thuần là một việc có lợi. Lấy ví dụ, mạch nối SCSI (SCSI bus) dùng bit chẵn lẻ để phát hiện lỗi trong truyền thông, và rất nhiều các phần lưu trữ trong bộ nhớ các lệnh vi xử lý (microprocessor instruction cache) cũng dùng bit chẵn lẻ để bảo trợ hoạt động của nó nữa. Do các dữ liệu trong I-cache[1] chỉ là một bản sao của bộ nhớ chính (main memory), nội dung của nó có thể được xóa đi, nạp lại nếu dữ liệu ở trong chẳng may bị thoái hóa (corrupted). Trong truyền thông dữ liệu nối tiếp (serial data transmission), dạng thức dữ liệu được dùng phổ thông nhất là dạng thức 7 bit, với một bit chẵn lẻ dùng quy luật số chẵn, và một hoặc hai bit dùng cho lệnh dừng lại. Dạng thức này thích ứng hầu hết các dạng thức 7-bit ký tự ASCII dưới hình thức byte 8-bit. Byte là một hình thức tiện lợi để biểu đạt dữ liệu. Những dạng thức khác cũng có thể thực hiện được, như dạng thức 8 bit dữ liệu cộng với một bit chẵn lẻ có thể dùng để chuyên chở tất cả các giá trị byte 8-bit. Trong ngữ cảnh của truyền thông nối tiếp (serial communication), bit chẵn lẻ thường được phát sinh và kiểm tra bởi phần cứng giao thức - chẳng hạn như UART - và khi thu nhận, CPU có thể sử dụng kết quả nhận được (và hệ điều hành nữa) thông qua bit báo tình hình (status bit) trong thanh ghi của phần cứng giao thức. Việc khôi phục lại sau khi tình trạng lỗi xảy ra thường được thi hành bằng cách tái truyền dữ liệu, và chi tiết của việc này thường là do phần mềm phụ trách (ví dụ dùng các thường trình nhập/xuất (I/O routine) của hệ điều hành). Khối chẵn lẻKhối chẵn lẻ (parity block) được dùng trong một số cấu hình RAID[2], và bằng cách dùng các khối chẵn lẻ, người ta đạt được tính dư thừa. Nếu một trong các ổ đĩa ở trong dãy đĩa bị hỏng, người ta có thể dùng các khối dữ liệu và các khối chẵn lẻ trong các đĩa còn làm việc để kiến tạo lại dữ liệu bị thất lạc (dữ liệu này nguyên ở trong cái đĩa bị hỏng). Trong biểu đồ vẽ sẵn dưới đây, mỗi cột là biểu tượng của một ổ đĩa. Giả sử A1 = 00000111, A2 = 00000101, and A3 = 0000000. Ap - phát sinh do xử lý XOR giữa A1, A2, và A3 - sẽ có giá trị bằng 00000010. Nếu ổ đĩa thứ hai bị hỏng và giá trị A2 không thể truy cập được, thì giá trị này có thể được kiến tạo lại bằng xử lý XOR A1, A3, và Ap như sau: A1 XOR A3 XOR Ap = 00000101 RAID Array A1 A2 A3 Ap B1 B2 Bp C1 C2 C3 C4 Cp Lưu ý: Các khối dữ liệu được đánh dấu theo hình thức A# (# ám chỉ một con số), khối chẵn lẻ là Ap (p = parity). b.Mã hai-trong-nămTrong những năm của thập niên kỷ 1940, Bell có sử dụng một mã hiệu phức tạp hơn một chút, gọi là mã hai-trong-năm (two-out-of-five code). Mã này đảm bảo mỗi một khối 5 bit (còn được gọi là khối-5) có chính xác hai bit có giá trị bằng 1. Máy tính có thể nhận ra là dữ liệu nhập vào có lỗi nếu trong một khối 5 bit không 2 bit có giá trị bằng 1. Tuy thế, mã hai-trong-năm cũng chỉ có thể phát hiện được một đơn vị bit mà thôi; nếu trong cùng một khối, một bit bị lộn ngược thành giá trị 1, và một bit khác bị lộn ngược thành giá trị 0, quy luật hai-trong-năm vẫn cho một giá trị đúng (remained true), và do đó nó không phát hiện là có lỗi xảy ra. c.Tái diễn dữ liệu Một mã nữa được dùng trong thời gian này là mã hoạt động bằng cách nhắc đi nhắc lại bit dữ liệu vài lần (tái diễn bit được truyền) để đảm bảo bit dữ liệu được truyền, truyền đến nơi nhận trọn vẹn. Chẳng hạn, nếu bit dữ liệu cần được truyền có giá trị bằng 1, một mã tái diễn n=3 sẽ cho truyền gửi giá trị "111". Nếu ba bit nhận được không giống nhau, thì hiện trạng này báo cho ta biết rằng, lỗi trong truyền thông đã xảy ra. Nếu kênh truyền không bị nhiễu, tương đối đảm bảo, thì với hầu hết các lần truyền, trong nhóm ba bit được gửi, chỉ có một bit là bị thay đổi. Do đó các nhóm 001, 010, và 100 đều tương đương cho một bit có giá trị 0, và các nhóm 110, 101, và 011 đều tương đương cho một bit có giá trị 1 - lưu ý số lượng bit có giá trị 0 trong các nhóm được coi là có giá trị 0, là đa số so với tổng số bit trong nhóm, hay 2 trong 3 bit, tương đương như vậy, các nhóm được coi là giá trị 1 có số lượng bit bằng 1 nhiều hơn là các bit có giá trị 0 trong nhóm - chẳng khác gì việc các nhóm bit được đối xử như là "các phiếu bầu" cho bit dữ liệu gốc vậy. Một mã có khả năng tái dựng lại thông điệp gốc trong một môi trường nhiễu lỗi được gọi là mã "sửa lỗi" (error-correcting code). Tuy nhiên, những mã này không thể sửa tất cả các lỗi một cách đúng đắn hoàn toàn. Chẳng hạn chúng ta có một ví dụ sau: nếu một kênh truyền đảo ngược hai bit và do đó máy nhận thu được giá trị "001", hệ thống máy sẽ phát hiện là có lỗi xảy ra, song lại kết luận rằng bit dữ liệu gốc là bit có giá trị bằng 0. Đây là một kết luận sai lầm. Nếu chúng ta tăng số lần các bit được nhắc lại lên 4 lần, chúng ta có thể phát hiện tất cả các trường hợp khi 2 bit bị lỗi, song chúng ta không thể sửa chữa chúng được (số phiếu bầu "hòa"); với số lần nhắc lại là 5 lần, chúng ta có thể sửa chữa tất cả các trường hợp 2 bit bị lỗi, song không thể phát hiện ra các trường hợp 3 bit bị lỗi. Nói chung, mã tái diễn là một mã hết sức không hiệu quả, giảm công suất xuống 3 lần so với trường hợp đầu tiên trong ví dụ trên của chúng ta, và công suất làm việc giảm xuống một cách nhanh tróng nếu chúng ta tăng số lần các bit được nhắc lại với mục đích để sửa nhiều lỗi hơn. còn nửa | |
| | | | nguyenkienkgs
Moderator
Tổng số bài gửi : 23
Registration date : 15/09/2007
| | Tiêu đề: Mã Hamming 14/10/2007, 20:21 | |
| IV. Mã HammingCàng nhiều bit sửa lỗi thêm vào trong thông điệp, và các bit ấy được bố trí theo một cách là mỗi bỗ trí của nhóm các bit bị lỗi tạo nên một hình thái lỗi riêng biệt, thì chúng ta có thể xác định được những bit bị sai. Trong một thông điệp dài 7-bit, chúng ta có 7 khả năng một bit có thể bị lỗi, như vậy, chỉ cần 3 bit kiểm tra (2^3 = 8 ) là chúng ta có thể, không những chỉ xác định được là lỗi trong truyền thông có xảy ra hay không, mà còn có thể xác định được bit nào là bit bị lỗi. Hamming nghiên cứu các kế hoạch mã hóa hiện có, bao gồm cả mã hai-trong-năm, rồi tổng quát hóa khái niệm của chúng. Khởi đầu, ông xây dựng một danh mục (nomenclature) để diễn tả hệ thống máy, bao gồm cả số lượng bit dùng cho dữ liệu và các bit sửa lỗi trong một khối. Chẳng hạn, bit chẵn lẻ phải thêm 1 bit vào trong mỗi từ dữ liệu (data word). Hamming diễn tả phương pháp này là mã (8,7). Nó có nghĩa là một từ dữ liệu có tổng số bit là 8 bit, trong đó chỉ có 7 bit là các bit của dữ liệu mà thôi. Theo phương pháp suy nghĩ này, mã tái diễn (nhắc lại) ở trên phải được gọi là mã (3,1). Tỷ lệ thông tin là tỷ lệ được tính bằng việc lấy con số thứ hai chia cho con số thứ nhất. Như vậy với mã tái diễn (3,1) ở trên, tỷ lệ thông tin của nó là 1/3 Hamming còn phát hiện ra nan đề với việc đảo giá trị của hai hoặc hơn hai bit nữa, và miêu tả nó là "khoảng cách" (distance) (hiện nay nó được gọi là khoảng cách Hamming (Hamming distance) - theo cái tên của ông). Mã chẵn lẻ có khoảng cách bằng 2, vì nếu có 2 bit bị đảo ngược thì lỗi trong truyền thông trở nên vô hình, không phát hiện được. Mã tái diễn (3,1) có khoảng cách là 3, vì 3 bit, trong cùng một bộ ba, phải bị đổi ngược trước khi chúng ta được một từ mã khác. Mã tái diễn (4,1) (mỗi bit được nhắc lại 4 lần) có khoảng cách bằng 4, nên nếu 2 bit trong cùng một nhóm bị đảo ngược thì lỗi đảo ngược này sẽ đi thoát mà không bị phát hiện. Cùng một lúc, Hamming quan tâm đến hai vấn đề; tăng khoảng cách và đồng thời tăng tỷ lệ thông tin lên, càng nhiều càng tốt. Trong những năm thuộc niên kỷ 1940, ông đã xây dựng môt số kế hoạch mã hóa. Những kế hoạch này đều dựa trên những mã hiện tồn tại song được nâng cấp và tiến bộ một cách sâu sắc. Bí quyết chìa khóa cho tất cả các hệ thống của ông là việc cho các bit chẵn lẻ gối lên nhau (overlap), sao cho chúng có khả năng tự kiểm tra lẫn nhau trong khi cùng kiểm tra được dữ liệu nữa. Thuật toán cho việc sử dụng bit chẵn lẻ trong 'mã Hamming' thông thường cũng tương đối đơn giản: 1. Tất cả các bit ở vị trí là các số mũ của 2 (powers of two) được dùng làm bit chẵn lẻ. (các vị trí như 1, 2, 4, 8, 16, 32, 64 v.v. hay nói cách khác 2^0, 2^1, 2^2, 2^3, 2^4, 2^5, 2^6 v.v.) 2. Tất cả các vị trí bit khác được dùng cho dữ liệu sẽ được mã hóa. (các vị trí 3, 5, 6, 7, 9, 10, 11, 12, 13, 14, 15, 17, etc.) 3. Mỗi bit chẵn lẻ tính giá trị chẵn lẻ cho một số bit trong từ mã (code word). Vị trí của bit chẵn lẻ quyết định chuỗi các bit mà nó luân phiên kiểm tra và bỏ qua (skips). * Vị trí 1 (n=1): bỏ qua 0 bit(n-1), kiểm 1 bit(n), bỏ qua 1 bit(n), kiểm 1 bit(n), bỏ qua 1 bit(n), v.v. * Vị trí 2(n=2): bỏ qua 1 bit(n-1), kiểm 2 bit(n), bỏ qua 2 bit(n), kiểm 2 bit(n), bỏ qua 2 bit(n), v.v. * Vị trí 4(n=4): bỏ qua 3 bit(n-1), kiểm 4 bit(n), bỏ qua 4 bit(n), kiểm 4 bit(n), bỏ qua 4 bit(n), v.v. * Vị trí 8(n= 8 ): bỏ qua 7 bit(n-1), kiểm 8 bit(n), bỏ qua 8 bit(n), kiểm 8 bit(n), bỏ qua 8 bit(n), v.v. * Vị trí 16(n=16): bỏ qua 15 bit(n-1), kiểm 16 bit(n), bỏ qua 16 bit(n), kiểm 16 bit(n), bỏ qua 16 bit(n), v.v. * Vị trí 32(n=32): bỏ qua 31 bit(n-1), kiểm 32 bit(n), bỏ qua 32 bit(n), kiểm 32 bit(n), bỏ qua 32 bit(n), v.v. * và tiếp tục như trên. Nói cách khác, bit chẵn lẻ tại vị trí 2k kiểm các bit ở các vị trí bit k có giá trị bằng 1(2) (the bit is set). Ngược lại, lấy ví dụ bit 13 chẳng hạn 1101(2), được kiểm bởi các bit 1000(2) = 8(10), 0100(2)=4(10) và 0001(2) = 1(10). còn nữa | |
| | | | nguyenkienkgs
Moderator
Tổng số bài gửi : 23
Registration date : 15/09/2007
| | Tiêu đề: Ví dụ dùng (11,7) mã Hamming 15/10/2007, 16:55 | |
| Lấy ví dụ chúng ta có một từ dữ liệu dài 7 bit với giá trị là "0110101". Để chứng minh phương pháp các mã Hamming được tính toán và được sử dụng để kiểm tra lỗi, xin xem bảng liệt kê dưới đây. Chữ d (data) được dùng để biểu thị các bit dữ liệu và chữ p (parity) để biểu thị các bit chẵn lẻ (parity bits). Đầu tiên, các bit của dữ liệu được đặt vào vị trí tương thích của chúng, sau đó các bit chẵn lẻ cho mỗi trường hợp được tính toán dùng quy luật bit chẵn lẻ số chẵn Cách tính các bit chẵn lẻ trong mã Hamming (từ trái sang phải) Nhóm dữ liệu mới (new data word) - bao gồm các bit chẵn lẻ - bây giờ là "10001100101". Nếu chúng ta thử cho rằng bit cuối cùng bị thoái hóa (gets corrupted) và bị lộn ngược từ 1 sang 0. Nhóm dữ liệu mới sẽ là "10001100100"; Dưới đây, chúng ta sẽ phân tích quy luật kiến tạo mã Hamming bằng cách cho bit chẵn lẻ giá trị 1 khi kết quả kiểm tra dùng quy luật số chẵn bị sai. Kiểm tra các bit chẵn lẻ (bit bị đảo lộn có nền thẫm) Bước cuối cùng là định giá trị của các bit chẵn lẻ (nên nhớ bit nằm dưới cùng được viết về bên phải - viết ngược lại từ dưới lên trên). Giá trị số nguyên của các bit chẵn lẻ là 11(10), và như vậy có nghĩa là bit thứ 11 trong nhóm dữ liệu (data word) - bao gồm cả các bit chẵn lẻ - là bit có giá trị không đúng, và bit này cần phải đổi ngược lại.  Việc đổi ngược giá trị của bit thứ 11 làm cho nhóm 10001100100 trở lại thành 10001100101. Bằng việc bỏ đi phần mã Hamming, chúng ta lấy được phần dữ liệu gốc với giá trị là 0110101.  Lưu ý, các bit chẵn lẻ không kiểm tra được lẫn nhau, nếu chỉ một bit chẵn lẻ bị sai thôi, trong khi tất cả các bit khác là đúng, thì chỉ có bit chẵn lẻ nói đến là sai mà thôi và không phải là các bit nó kiểm tra (not any bit it checks). Cuối cùng, giả sử có hai bit biến đổi, tại vị trí x và y. Nếu x và y có cùng một bit tại vị trí 2k trong đại diện nhị phân của chúng, thì bit chẵn lẻ tương ứng với vị trí đấy kiểm tra cả hai bit, và do đó sẽ giữ nguyên giá trị, không thay đổi. Song một số bit chẵn lẻ nào đấy nhất định phải bị thay đổi, vì x ≠ y, và do đó hai bit tương ứng nào đó có giá trị x và y khác nhau. Do vậy, mã Hamming phát hiện tất cả các lỗi do hai bit bị thay đổi — song nó không phân biệt được chúng với các lỗi do 1 bit bị thay đổi. Còn nữa | |
| | | | nguyenkienkgs
Moderator
Tổng số bài gửi : 23
Registration date : 15/09/2007
| | Tiêu đề: Mã Hamming (7,4) 15/10/2007, 16:57 | |
| Mã Hamming (7,4)Hiện thời, khi nói đến mã Hamming chúng ta thực ra là muốn nói đến mã (7,4) mà Hamming công bố năm 1950. Với mỗi nhóm 4 bit dữ liệu, mã Hamming thêm 3 bit kiểm tra. Thuật toán (7,4) của Hamming có thể sửa chữa bất cứ một bit lỗi nào, và phát hiện tất cát lỗi của 1 bit, và các lỗi của 2 bit gây ra. Điều này có nghĩa là đối với tất cả các phương tiện truyền thông không có chùm lỗi đột phát (burst errors) xảy ra, mã (7,4) của Hamming rất có hiệu quả (trừ phi phương tiện truyền thông có độ nhiễu rất cao thì nó mới có thể gây cho 2 bit trong số 7 bit truyền bị đảo lộn). Ví dụ về cách dùng các ma trận thông qua GFcác bạn có thể down về máy xem vì mình không biết đánh mấy hàm tóan học trên forum: http://www.mediafire.com/?dc2aaxzcm2zcòn nữa
Được sửa bởi ngày 15/10/2007, 17:08; sửa lần 1. | |
| | | | nguyenkienkgs
Moderator
Tổng số bài gửi : 23
Registration date : 15/09/2007
| | Tiêu đề: Mã Hamming và bit chẵn lẻ bổ sung 15/10/2007, 16:59 | |
| Nếu chúng ta bổ sung thêm một bit vào mã Hamming, thì mã này có thể dùng để phát hiện những lỗi gây ra do 2 bit bị lỗi, và đồng thời nó không cản trở việc sửa các lỗi do một bit gây ra. [1] Nếu không bổ sung một bit vào thêm, thì mã này có thể phát hiện các lỗi do một bit, hai bit, ba bit gây ra, song nó sẽ cản trở việc sửa các lỗi do một bit bị đảo lộn. Bit bổ sung là bit được áp dụng cho tất cả các bit sau khi tất cả các bit kiểm của mã Hamming đã được thêm vào.
Khi sử dụng tính sửa lỗi của mã, nếu lỗi ở một bit chẵn lẻ bị phát hiện và mã Hamming báo hiệu là có lỗi xảy ra thì chúng ta có thể sửa lỗi này, song nếu chúng ta không phát hiện được lỗi trong bit chẵn lẻ, nhưng mã Hamming báo hiệu là có lỗi xảy ra, thì chúng ta có thể cho rằng lỗi này là do 2 bit bị đổi cùng một lúc. Tuy chúng ta phát hiện được nó, nhưng không thể sửa lỗi được.
Tài liệu được lấy từ websile Wikipedia | |
| | | | nguyenkienkgs
Moderator
Tổng số bài gửi : 23
Registration date : 15/09/2007
| | Tiêu đề: Hướng Dẫn Dung C++ viết chương trình ma hamming 24/10/2007, 09:35 | |
| Bài này mình hướng dẫn viết chương trình nhập vào m bit dữ liệu , số lượng bít mã hóa , xuất kết quả ra màn hình m bit du liêu và n = m+r bit sau khi đã được mã hóa .
Đối với bài này quan trong nhất là thuật tóan tim p[i] . Mình có một cách có thể tính được p là tạo 1 mang nxr phần tử .
- Đầu tiên các bạn gán cho a[i][j] ==2 bởi vì số 2 rất giống với số 0 và dùng để phan biệt vị trí có bít dữ liệu 0 và vị trí bỏ chống .
- Dùng vòng lâp để hạ các bít dữ liệu vào vị trí cần hạ . còn lại những vị trí nào k có dữ liệu thi nhân gía trị 2 ban đầu .
- Đến dây chúng ta có thể tìm được p[i] bàng cách dùng dòng lập for để đếm từ 1 đến n và kiểm tra nếu dem mà chẵn thì p[i] có giá trị 0 và lẻ có giá trị 1 .
Kết cấu của bài mình làm theo suờn :
- Tạo hàm nhập mảng dữ liệu .
- Tạo hàm xuất mảng dữ liệu .
- Tạo hàm lưu dữ liệu vào ma trận nxr
+ Tạo ma trận chứa giá trị =2
+ Tạo ma trận thay thế vị chí nào có chứa dữ liệu vào thì chứa còn lại vẫn lấy giá trị là 2 .
+ Có ma trận rồi bầy giờ kiểm tra dể gán giá trị p[1]=0 or 1
- Có thể tạo hàm xuất ma trận ra man hình để dễ kiểm tra các bước mình làm .
- Tạo mảng mã hóa n phần tử . sau đó lấy giá trị p[i] và dữ liệu chuẩn ban đầu nhập sắp vào vị trí cần sắp .
- Tạo chương trình chính đẻ thực thi .
Chú ý : khi dùng biến con trỏ nếu tạo ô nhớ dộng để sử dụng thì khi dung song phải sóa ô nhớ dó đi . nếu không sẽ bị chàn bộ nhớ .
Cách này mình làm k dược tối ưu vì nó dùng rất nhiều bộ nhớ . bạn nào có cách nào ngắn hơn và tối ưu hơn thì đăng lên cho bà con tham khảo . | |
| | | | Sponsored content
| | Tiêu đề: Re: Mã Hamming | |
| |
| | | | | | Mã Hamming | |
|
| Trang 1 trong tổng số 1 trang | |
| | Permissions in this forum: | Bạn không có quyền trả lời bài viết
| |
| |
| |
|